La Inteligencia Artificial (IA) se ha convertido en una herramienta transformadora para la bioseguridad, definida como el conjunto de medidas destinadas a proteger la salud humana, animal, vegetal y el medio ambiente frente a riesgos biológicos (virus, bacterias, toxinas, etc.). Sin embargo, la convergencia entre IA y biotecnología (AIxBio) representa un doble filo: acelera enormemente la capacidad de respuesta a amenazas, pero también reduce barreras para la creación de patógenos peligrosos, ya sea por accidente o mal uso intencional.
En 2026, la IA ya no solo apoya la ciencia biológica, sino que comienza a diseñar y ejecutar experimentos de forma semi-autónoma, obligando a actualizar urgentemente los marcos de bioseguridad tradicionales (como el BMBL del CDC).
1. Aplicaciones positivas de la IA en Bioseguridad
a) Vigilancia epidemiológica y detección temprana de brotes Los sistemas de IA procesan en tiempo real grandes volúmenes de datos heterogéneos: redes sociales, búsquedas en internet, historias clínicas, datos de ventas de medicamentos, información meteorológica, movilidad humana y secuencias genómicas. Esto permite identificar señales anómalas semanas antes de que los sistemas tradicionales confirmen un brote. La OMS actualizó en 2025 su sistema EIOS (Epidemic Intelligence from Open Sources) incorporando IA para mejorar el análisis automatizado y la detección de señales. Estas herramientas también se integran con datos de aguas residuales y metagenómica ambiental.
b) Monitoreo inteligente en laboratorios de alta contención (BSL-3 y BSL-4) Sistemas de visión por computadora verifican en tiempo real el uso correcto del Equipo de Protección Personal (EPP), detectando faltantes o mal ajustes. Monitorean continuamente presión negativa, flujo de aire HEPA, temperatura y posibles fugas, generando alertas automáticas y prediciendo fallos de mantenimiento. La automatización con robots e IA reduce la exposición humana directa a patógenos peligrosos.
c) Diseño acelerado de contramedidas Modelos como AlphaFold (y versiones posteriores) predicen con alta precisión la estructura 3D de proteínas virales o bacterianas, acelerando el diseño de vacunas, anticuerpos monoclonales, antivirales y diagnósticos. En 2025 se avanzó en vacunas basadas en diseño computacional asistido por IA. Iniciativas como la “100 Days Mission” de CEPI buscan desarrollar contramedidas en solo 100 días. La IA optimiza plataformas de ARNm y permite respuestas rápidas ante patógenos emergentes.
d) Evaluación y gestión de riesgos La IA ayuda a clasificar experimentos de “doble uso” (Dual Use Research of Concern – DURC), evaluando si un procedimiento podría aumentar transmisibilidad, letalidad o resistencia de un patógeno. Herramientas de cribado analizan secuencias de ADN/ARN antes de sintetizarlas, bloqueando aquellas de alto riesgo.
e) Seguridad y salud ocupacional La IA analiza datos de wearables para monitorear signos vitales, fatiga y exposición potencial. Detecta comportamientos inseguros y automatiza tareas repetitivas en “cloud labs”, reduciendo la intervención humana con agentes infecciosos. La OIT destaca cómo la IA mejora la seguridad y salud en el trabajo.
2. Riesgos y desafíos: la cara oscura de la IA en bioseguridad
La convergencia AIxBio baja drásticamente las barreras técnicas, económicas y de conocimiento para crear amenazas biológicas.
a) Diseño de proteínas y patógenos novedosos Modelos generativos crean secuencias de proteínas o ácidos nucleicos completamente nuevas. En 2025, IA diseñó virus (bacteriófagos) funcionales que infectan y matan bacterias específicas, demostrando el potencial para aplicar la misma tecnología en patógenos humanos.
b) “Zero-day” biológicos La IA genera patógenos o toxinas que no existen en la naturaleza y que evaden los sistemas actuales de cribado de síntesis de ADN. Estudios mostraron que variantes rediseñadas por IA pueden eludir filtros de proveedores.
c) Automatización de experimentos Laboratorios robóticos + IA permiten diseñar, planificar y ejecutar miles de experimentos con mínima intervención humana. En 2026, casos como la colaboración entre OpenAI y Ginkgo Bioworks muestran IA ejecutando decenas de miles de experimentos biológicos de forma autónoma.
d) Deskalilling (reducción de habilidades requeridas) Personas sin experiencia en biología, asistidas por IA, completan tareas complejas de virología con mayor precisión. Estudios de SecureBio indican que no expertos superaron a expertos en ciertas tareas y obtuvieron instrucciones detalladas pese a filtros de seguridad.
e) Riesgo de mal uso (bioterrorismo o accidente) Expertos de SecureBio, NTI, RAND y el International AI Safety Report 2026 advierten que la IA aumenta significativamente el riesgo de armas biológicas de alto impacto. Modelos pueden proporcionar instrucciones detalladas de laboratorio y ayudar a superar barreras tradicionales.
3. Medidas de mitigación actuales y propuestas (2026)
a) Screening de secuencias de ADN/ARN Proveedores bloquean pedidos que coincidan con patógenos regulados, pero la IA genera variantes que evaden estos filtros. El screening sigue siendo mayoritariamente voluntario en muchos países.
b) Evaluaciones de seguridad previas al lanzamiento Empresas realizan pruebas internas (“safety evaluations”) y agregan salvaguardas. Se proponen benchmarks como el Virology Capabilities Test (VCT) de SecureBio.
c) Gobernanza y regulación Se discuten accesos gestionados (tiered access), licencias para modelos de alto riesgo, supervisión humana obligatoria y auditorías independientes. En EE.UU. hay avances en NDAA 2026 y propuestas bipartidistas. A nivel internacional se debate en la Convención sobre Armas Biológicas (BWC). Organizaciones como NTI recomiendan colaboración entre gobiernos, empresas de IA y científicos.
d) Mejora de filtros y salvaguardas en los modelos de IA Se implementan rechazos (“refusals”) más robustos, aunque vulnerables a jailbreaking. Se exploran técnicas de alineación y entrenamiento con datos filtrados.
e) Cribado de clientes (“know your customer”) Verificación de legitimidad de usuarios y proyectos en síntesis de ADN y acceso a modelos biológicos.
Resumen: Oportunidades vs Riesgos
Aspecto
Beneficio principal
Riesgo principal
Vigilancia
Detección temprana con datos masivos
Evasión de sistemas o generación de desinformación
Laboratorios
Monitoreo 24/7 y menor exposición humana
Automatización de experimentos de alto riesgo sin supervisión experta
Diseño de moléculas
Vacunas y fármacos en tiempo récord
Patógenos novedosos más letales o indetectables
Accesibilidad
Avances médicos democráticos
Baja barrera para actores maliciosos o inexpertos
Gobernanza
Herramientas para evaluar riesgos
Brecha entre velocidad tecnológica y marcos regulatorios
En 2026, la IA está cerrando el bucle entre diseño y ejecución biológica. Esto exige actualizar manuales de bioseguridad y crear regulaciones específicas para AIxBio.
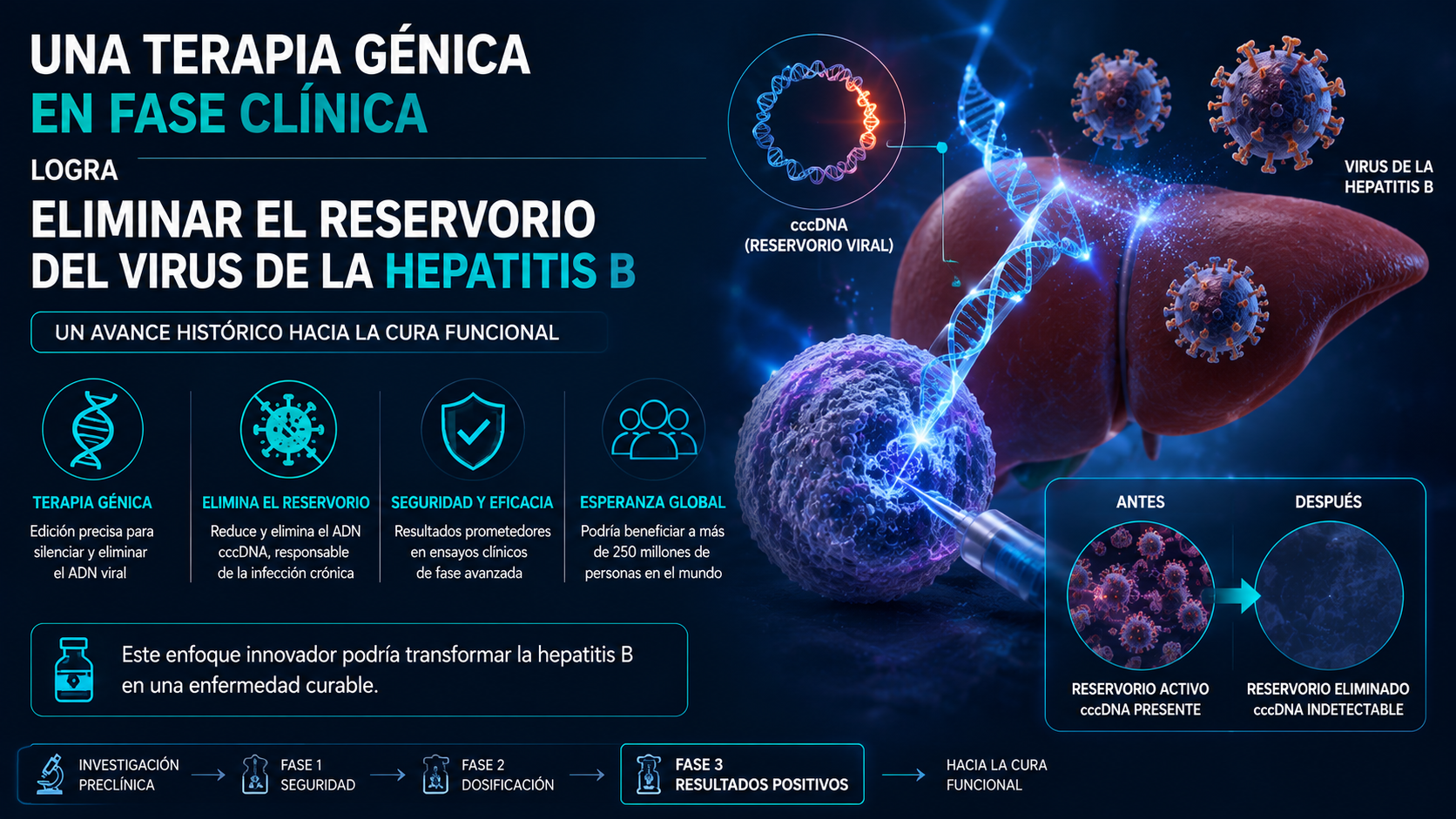
Precision Biosciences reportó los primeros resultados clínicos de PBGENE-HBV, una terapia de edición génica in vivo basada en su plataforma ARCUS, que logró evidencia directa de eliminación e inactivación del ADNccc del virus de la hepatitis B, el reservorio viral que sostiene la infección crónica en el hígado y que hasta ahora ningún tratamiento disponible podía erradicar de forma definitiva.
Biopsias hepáticas de los pacientes tratados mostraron una reducción de los transcriptos de ADNccc, mientras que la totalidad de los pacientes evaluables perdió los niveles detectables de pgRNA, un marcador clave de replicación viral activa. A diferencia de los tratamientos antivirales actuales para la hepatitis B, que logran suprimir la replicación del virus pero deben mantenerse de por vida porque no eliminan el reservorio viral latente en el núcleo de las células hepáticas, la plataforma ARCUS de Precision Biosciences fue diseñada específicamente para cortar y desactivar ese ADN viral remanente de forma dirigida.
Para la industria de la biotecnología, este resultado temprano —aunque todavía preliminar— representa una prueba de concepto significativa: la hepatitis B crónica afecta a cientos de millones de personas en el mundo, y la ausencia de una cura definitiva ha sido durante décadas uno de los mayores desafíos no resueltos de la hepatología. Que una terapia de edición génica in vivo logre evidencia clínica de eliminación del reservorio viral abre una vía de desarrollo que distintas compañías de edición genética vienen persiguiendo en paralelo, con distintas plataformas de enzimas y sistemas de entrega.
Para los pacientes, la perspectiva de una terapia potencialmente curativa y de dosis finita —en lugar de un tratamiento antiviral de por vida— cambiaría de forma radical el manejo clínico de la enfermedad, aunque todavía restan etapas regulatorias y clínicas extensas antes de que un tratamiento así llegue a estar disponible de forma masiva. El caso también reabre el debate de fondo sobre los costos y el acceso equitativo a terapias génicas curativas, que hasta ahora han tendido a ser extremadamente costosas en su lanzamiento comercial.
Fuentes al pie:
CRISPR Medicine News: https://crisprmedicinenews.com/news/cmn-weekly-26-june-2026-your-weekly-crispr-medicine-news/
Esta nota amplía la cobertura previa del portal sobre CRISPR-Cas12a2. Un nuevo trabajo del laboratorio de Jennifer Doudna describe un sistema que detecta mutaciones específicas del gen p53 en células cancerosas y las induce a autodestruirse, entregado mediante nanopartículas lipídicas que se dirigen preferentemente al pulmón.
El enfoque desarrollado por el equipo de Doudna se aparta de la estrategia clásica de bloquear la proteína p53 mutada: en cambio, el sistema CRISPR-Cas12a2 identifica los transcriptos de ARN mutantes de p53 y cambia a un modo destructivo, fragmentando el ADN de la célula y provocando esencialmente que la célula cancerosa se autoelimine. La especificidad del mecanismo es notable porque las guías moleculares apuntan a un cambio de una sola letra en el ARN, dejando intactas a las células que no portan esa mutación puntual, un nivel de precisión que reduce el riesgo de daño a tejido sano circundante.
La entrega del sistema utiliza ARN mensajero encapsulado en nanopartículas lipídicas diseñadas con componentes que las dirigen preferentemente hacia el pulmón, a diferencia de las nanopartículas lipídicas estándar que tienden a acumularse en el hígado. Esta particularidad de entrega es clave porque las mutaciones de p53 están entre las más comunes en distintos tipos de cáncer, y contar con una plataforma que además pueda transportar varias guías simultáneamente significa que un mismo tratamiento podría apuntar a múltiples mutaciones causantes de cáncer a la vez, en lugar de requerir terapias separadas para cada alteración genética específica.
El impacto de este desarrollo se inscribe en la misma familia tecnológica que ya cubrió este portal en la plataforma GuardianConve, orientada a la detección temprana y eliminación selectiva de células tumorales con CRISPR-Cas12a2 e infraestructura de NVIDIA. La diferencia central es que este nuevo trabajo de Doudna se concentra específicamente en el mecanismo de destrucción dirigida contra mutaciones de p53 y en la vía de entrega pulmonar, un paso que profundiza la validación científica de base detrás de ese tipo de plataformas diagnóstico-terapéuticas que combinan CRISPR con inteligencia artificial y nanotecnología de entrega.
La dimensión humana de este avance es directa: el gen p53, apodado por muchos investigadores como «el guardián del genoma», está mutado en aproximadamente la mitad de todos los cánceres humanos, por lo que cualquier estrategia capaz de atacar selectivamente esas mutaciones sin dañar tejido sano representa una vía terapéutica de alto impacto potencial. Restan, de todos modos, años de validación preclínica y clínica antes de que este tipo de enfoque llegue a pacientes reales, y la comunidad científica seguirá de cerca si la especificidad observada en el laboratorio se mantiene en organismos completos y, eventualmente, en ensayos humanos.
Fuentes: Works in Progress: https://www.worksinprogress.news/p/whats-new-in-biology-july-2026
El laboratorio de Dieter Egli en Columbia probó en un entorno de investigación una técnica de edición de bases sobre embriones humanos, un método considerado más seguro que el CRISPR-Cas9 clásico porque evita cortar ambas cadenas de ADN. El hallazgo reabre, con nuevas salvaguardas técnicas, un debate ético que había quedado congelado desde el escándalo de He Jiankui en 2018.
La técnica de edición de bases, a diferencia del CRISPR-Cas9 estándar que corta ambas hebras de la doble hélice de ADN, modifica directamente una única letra genética sin generar una rotura de doble cadena, el tipo de daño que resulta más difícil de reparar para la célula y que puede provocar la pérdida de fragmentos largos de ADN o incluso de cromosomas enteros. El equipo de Dieter Egli en la Universidad de Columbia ya había probado en 2020 la edición clásica en un entorno de investigación y encontró que cerca de la mitad de los embriones sufrían lo que el propio investigador calificó como «consecuencias catastróficas». La nueva prueba con edición de bases busca precisamente evitar ese tipo de daño estructural masivo.
El contexto histórico de este trabajo es ineludible: hace ocho años, el científico chino He Jiankui se convirtió en una figura infame de la ciencia mundial al usar CRISPR-Cas9 para editar embriones de fecundación in vitro que efectivamente nacieron como niños, en lo que trascendió como mucho más que un escándalo ético sobre edición genética, ya que expuso los riesgos técnicos reales de una tecnología aplicada de forma prematura y sin las salvaguardas adecuadas. Desde entonces, la comunidad científica internacional avanzó con extrema cautela en experimentos de investigación —sin implantación ni gestación— que buscan primero resolver los problemas de seguridad técnica antes de cualquier consideración de uso clínico real.
El impacto potencial de esta línea de investigación, si eventualmente madura hacia aplicaciones seguras, apunta a la corrección de mutaciones de una sola letra que causan numerosas enfermedades congénitas. La idea, según describe el propio trabajo, es que embriones detectados durante un proceso de fecundación in vitro que porten este tipo de mutaciones —y que hoy los padres podrían optar por descartar— podrían en el futuro ser corregidos antes de la implantación, evitando así la transmisión de la enfermedad sin necesidad de descartar el embrión.
La dimensión ética y social de este avance es, casi por definición, tan relevante como la técnica: la edición de la línea germinal humana —aquella que se transmite a la descendencia— sigue prohibida para uso clínico en la enorme mayoría de los países, precisamente por las implicancias irreversibles de cualquier error y por el precedente que sentaría sobre la selección de características heredables. Que un laboratorio de investigación serio logre reducir el riesgo técnico de la edición de embriones no despeja, sin embargo, las preguntas regulatorias y filosóficas sobre quién debe decidir qué mutaciones corregir y dónde trazar el límite entre terapia y mejora genética.
Fuentes: Works in Progress: https://www.worksinprogress.news/p/whats-new-in-biology-july-2026

























 AI1 año ago
AI1 año ago
 Nano1 año ago
Nano1 año ago
 AI8 meses ago
AI8 meses ago
 AI1 año ago
AI1 año ago